注意:文中许多算法设计是根据《算法笔记》1 来写的。
排序 Sort
- 冒泡排序 Bubble Sort
- 思想:每趟中,依次比较两个相邻元素,传递式地在将一个最值传递到端
- 评价:$O(n^2)$
- 选择排序 Selection Sort
- 思想:每趟中,找到最值置于一端
- 评价:$O(n^2)$
- 插入排序 Insertion Sort
- 思想:原始序列一切为二,有序和无序。每一趟,从无序中取一个插入有序的。类比整理纸牌。
- 评价:$O(n^2)$
- 归并排序 Merge Sort
- 思想:二分思想,每次归并两个不相交的部分。
- 实现:merge 函数,合并两个不相交的两部分,拉链式合并到新数组,最后用 memcpy;merge_sort 函数,利用辅助函数 merge 递归地或迭代地合并
- 评价:$O(nlogn)$
- 快速排序 Quick Sort
- 思想:two pointers,分而治之。按主元分割序列。另外,快排也体现出一种随机选择(Random Selection)的思想。
- 实现:partition 函数,以 two pointers 的方法将序列分割成两个部分,返回主元(prime)下标;quick_sort 函数,分而治之地使用 partition 函数
- 评价:$O(nlogn)$
- 堆排序 Heap Sort
- 思想:利用堆优先队列的性质
- 实现:不断取堆顶置于末尾
- 评价:$O(nlogn)$
代码模板
| |
查找 Search
二分查找 Binary Search
- while 循环中是 left <= right or left < right
- 接收参数 left,right 所代表的区间开闭
- 判断时的 array[mid] > or < or >= or <= x
- 不满足情况时的返回值
- 返回值返回什么
代码模板
| |
散列 Hash
散列本质上是查找算法。常用的哈希函数 hash(key) = key % table_size,其中 table_size 尽量为素数,减少冲突(collision)。其他处理冲突的方法:
- 线性探查法(Linear Probing):若冲突,则
hash(key) = (key + 1) % table_size; - 平方探查法(Quadratic Probing):若冲突,则
hash(key) = (key ± n²) % table_size; - 链表法:
hash(key)值相同的保存在相同的链表节点上
深度优先搜索 Depth First Search
| |
DFS 例题
广度优先搜索 Breath First Search
关键点:
- Node 结构体
- 标识数组,如 in_queue,is_visisted,map 变量,set 变量
- bfs
- 参数:首元素
- 首元素入队,首元素进行一般性操作
- 循环:通过首元素找下一层元素
| |
BFS 例题
PAT A1091 “Acute Stroke”,点此处,并在以下目录
solutions/solutions-PAT/A1091.cpp中查看题解。CODEUP 100000609-03 “【宽搜入门】魔板”,点此处,并在以下目录
solutions/solutions-CODEUP/100000609-03.cpp中查看题解。
数学 Mathematics
快速幂 Fast Power
快速幂的核心原理是 $a^{m+n} = a^m + a^n$
代码模板
| |
最大公约数和最小公倍数 Greatest Common Divisor & Least Common Multiple
更相减损法:直接假设 a > b,则 gcd(a, b) = gcd(b, a%b)
代码模板
| |
素数 Prime Number
- 平方技术:判断给定数字是否是素数
- 埃氏(Eratosthenes)筛法:求某范围内的所有素数,原理在于素数不是任何非 1 与非本身数字的倍数,因此从 2 开始枚举所有的倍数,枚举 3 所有的倍数…
代码模板
| |
取整与舍入 Round
- 向下取整
- C 函数:
Rounded_down(double x) = int(x)
- C 函数:
- 向上取整
- 数学公式:$Ru(x) = \lfloor x \rfloor + 1 - \lfloor 1.0 \cdot \lfloor x + 1 \rfloor - x \rfloor$
- C 函数:
Rounded_up(double x) = int(x) + 1 - int(1.0*int(x+1)-x)
- 向上取整的整除
- C 函数:
Rounded_up(int a, int b) = (a - 1) / b + 1; - 或
Rounded_up(int a, int b) = (a + b - 1) / b,其中b - 1是偏置量(biasing),这种方法常见于对负数算术右移的舍入中
- C 函数:
- 四舍五入
- C 函数:
Round(double x) = int(x + 0.5)
- C 函数:
- 上下取整的关系
- 数学公式:$\lceil x \rceil = \lfloor x \rfloor + \Delta,\quad \Delta = 1 - \lfloor 1.0 \cdot \lfloor x + 1 \rfloor - x \rfloor$
扩展欧几里得算法 Extended Euclidean algorithm
扩展欧几里得算法以 gcd 算法为基础,解决以下几个问题
问题 1:ax + by = gcd(a, b) 的整数解?
- 求解其中一组解:联立 $a \bmod b = a - (a / b) * b$ 与 $ax_0 + by_0 = bx_1 + (a \bmod b)y_2$
- 求解全部解:联立 $ax + by = gcd(a, b)$ 与 $a(x + s_1) + b(y - s_2) = gcd(a, b)$
- 求解最小正整数 x’ 的解:$x' = (x \bmod \frac{b}{gcd} + \frac{b}{gcd}) \bmod \frac{b}{gcd}$
代码模板
| |
问题 2:ax + by = c 的整数解?
若 $c \bmod gcd = 0$,则可以将问题转化 $ax + by = gcd \leftrightarrow a \frac{cx'}{gcd} + b \frac{cy'}{gcd} = c$
若 $c \bmod gcd ≠ 0$,则无解
问题 3:同余式 ax ≡ c(mod m) 的整数解?
$ax ≡ c(mod \ m)$ 等价于 $(ax - c) \bmod m = 0$ 等价于求解 $ax + my = c$ 中 x 的值
若 $c \bmod gcd(a, m) = 0$,则同余式恰好有 gcd(a, m) 个模 m 意义下不相同的解
若 $c \bmod gcd(a, m) ≠ 0$,则无解
问题 4:ax ≡ 1 中 a 逆元的求解?
模运算下的乘法逆元:若 $m > 1, ab ≡ 1(mod \ m)$,则 a 与 b 互为模运算下的乘法逆元。
ps. 找逆元主要是找到最小的正整数 x。
若 $gcd(a, m) = 1$,则 $ax ≡ 1(mod \ m)$ 在 (0, m) 上有唯一解;
若 $gcd(a, m) ≠ 1$,则无解。
问题 5:(b / a) % m 的值计算?
方法一:利用逆元
$\quad (b / a) \bmod m$
$\leftrightarrow (b * a') \bmod m$
$\leftrightarrow (b \bmod m) * (a \bmod m) \bmod m$
方法二:利用费马小定理
费马小定理:若 m 为素数且 a % m ≠ 0,则 $a^{m - 1} ≡ 1(mod \ m)$
易知,$a * a ^ {m - 2} ≡ 1(mod \ m)$,所以 $a ^ {m - 2}$ 即为逆元。通过快速幂即可求出。
方法三:硬求解
$\quad (b / a) \bmod m = x$
$\leftrightarrow b / a = km + x$
$\leftrightarrow b \bmod (am) / a = x$
全排列 Full Permutation
代码模板
| |
组合数学 Combinatorial Mathematics
组合数的计算问题与快速幂,素数筛选,阶乘质因子分解,扩展欧几里得算法等相关。组合数算法是这些算法的综合应用。
问题 1:n! 中质因子的数量
不断除以 p 来找到规律。可以使用递推或递归求解。
问题 2:$C^m_n$ 的计算
方法一:递推公式 $C^m_n = C^{m-1}_{n-1} + C^m_{n-1}$
方法二:公式变形,边乘边除
问题 3:$C^m_n \bmod p$ 的计算
方法一:递推公式
$C^m_n = (C^{m-1}_{n-1} + C^m_{n-1}) \bmod p$
方法二:定义式 + 组合中各阶乘的质因子分解
计算出 $C^m_n = \frac{n!}{m!(n-m)!}$ 中,即 n!, m!, (n-m)! 中每个的 $P_i$ 的个数,然后快速幂求解
方法三:m < p, p 是素数时,
利用逆元求解
找到分母中每一个的逆元
方法四:m 任意,p 是素数时,
去除分子分母中多余素数 p + 边乘边除 + 逆元求解
去除多余 p 归一,然后用方法三
方法五:m,p 均任意时,
① 对 p 进行质因子分解;
② 对分子分母中每一项都进行质因子分解
分解 p 归一,然后用方法四
方法六:Lucas 定理
计算 $C^m_n \bmod p$ 时,若 p 为素数,将 m 和 n 表示为 p 进制:
$m = m_kp^k+m_{k-1}p^{k-1}+...+m_0$
$n = n_kp^k+n_{k-1}p^{k-1}+...+n_0$
则 $C^m_n \bmod p \equiv C_{n_k}^{m_k} C_{n_{k-1}}^{m_{k-1}} ... C_{n_0}^{m_0} \bmod p$
代码模板
| |
欧拉公式 Euler’s Formula
$V+E-F=2$
基姆拉尔森公式 Kim Larson Formula
是日期到星期的转换公式
| |
高精度整数 Big Integer
- 只要掌握“高精度 × int”,该类型的题就迎刃而解了
- “高精度 × int”:高精度拆分成 bit,bit 乘 int,结果 carry 累加
代码模板
| |
分数 Fraction
代码模板
| |
链表 Linked List
部分线性表之间的关系
- 线性表
- 顺序表 - 数组
- 链表
- 动态链表
- 静态链表
动态链表 Dynamic Linked List
链表内存空间在使用过程中动态生成与消灭
步骤一:定义节点
| |
步骤二:内存空间管理
| |
| |
静态链表 Static Linked List
因为问题规模确定且较小,实现分配好空间的链表。这类题目有较为一般的解题步骤:
Define -> Initialize -> Purge -> Sort -> Output
Step 1: Define
| |
Step 2: Initialize
| |
Step 3: Purge
| |
Step 4: Sort
| |
Step 5: Output
| |
静态链表例题
PAT B1025 “反转链表”,点此处,并在以下目录
solutions/solutions-PAT/B1025.cpp中查看题解。PAT A1097 “Deduplication on a Linked List”,点此处,并在以下目录
solutions/solutions-PAT/A1097.cpp中查看题解。
树 Tree
分类 Classification
树形态上的分类
- 树 Tree
- 二叉树 Binary Tree
- 完全二叉树 Complete Binary Tree:只允许右下角为空的二叉树
- 满二叉树:每一层均满的二叉树,形状如三角形,是特殊的完全二叉树
- Full Binary Tree:结点或为叶子或度为 2 的树(想象最常见的哈夫曼树)
- 完全二叉树 Complete Binary Tree:只允许右下角为空的二叉树
- 二叉树 Binary Tree
ps. 满二叉树和 Full Binary Tree 含义并不相同,中外间有歧义。中文语境下使用满二叉树概念即可。
树实现上的分类
- 动态的树:节点指针域使用地址索引,随时创建节点
- 含数据域的节点
- 另外包含层次号
layer或level的节点
- 静态的树:节点指针域使用下标索引,创建固定大小的树
- 普通的静态树
- 二维化的树:对于完全二叉树来说,若从 1 开始层次化顺次索引,则任一节点 n 的左子节点为 2n,右子节点为 2n+1
二叉树 Binary Tree
一般二叉树 General Binary Tree
二叉树是指节点度不超过 2 的树。有以下关键点必须掌握:
- 定义节点:
struct Node节点 = 数据 + 左孩子 + 右孩子 (+ 层次号) - 新建节点:
Node* new_node(int val)记得初始化指针域 - 插入新节点:
void insert(Node* &root, int data)碰到创建新节点的地方,都要用引用 - 四种遍历:如
void preorder(Node* root) - 复原二叉树:如
Node* create_by_pre_in中序遍历和其他三种遍历结合都可以复原一棵二叉树
ps. 预设二叉树一般不含重复值的节点
代码模板
| |
二叉查找树 Binary Search Tree
二叉查找树是有序的二叉树。在一般二叉树的基础上,还要掌握:
- 插入新节点:加入分支判断使二叉树满足有序的性质
- 删除元素:
void delete_node(Node* &root, int x)重点是保证删除后仍满足有序的性质。最简单的实现包括三层任务- 递归地找到节点 x
- 找前、后驱(如果都没有,直接删除即可),要用到两个辅助函数,如
Node* find_min(Node* root):寻找以 root 为根节点的树中最小权值节点
- 复制前驱值到当前节点,递归删除前驱节点
代码模板
| |
平衡二叉树 AVL Tree
AVL 树加速 BST 查找速度。在 BST 的基础上,要掌握插入新节点的方法:
- 定义节点:加入 height 参数,以便计算平衡因子
- 两个获取参数的函数:
int get_height(Node* root)int get_balance_factor(Node* root)
- 一个更新函数,应对插入后高度的变化:
void update_height(Node* root) - 两个旋转树的函数,以降低 root 的平衡因子:
void left_rotation(Node* &root)void right_rotation(Node* &root)
- insert 函数:通过平衡因子,判断 LL、LR、RR、RL 四种插入情形进行旋转
代码模板
| |
堆 Heap
堆的本质是一颗有序的 CBT。其应用包括优先队列、堆排序等。主要应掌握以下内容:
- 定义堆:一般是二维化的完全二叉树式的实现形式
- 定义堆的数组、堆的大小(一般采用全局变量)
- 堆数组下标从 1 开始计数
- 明确是大顶堆还是小顶堆
- 辅助的调整函数
- 包括
void down_adjust(int low, int high)和void up_adjust(int low, int high) - 包括递归和迭代两种实现方法,其中递归的要注意好递归边界的定义
- 只用微改调整函数,就可以切换大顶堆 or 小顶堆
- 包括
- 建堆:假设数组中已有初值,从最后一个非叶子节点向前进行
down_adjust - 删除堆顶元素:末尾元素置顶,长度减一,
down_adjust - 添加元素:元素缀于末尾,
up_adjust
堆的两个性质,实质上就是 CBT 的性质:
- $CBT 节点数 = 叶子节点数 + 非叶子节点数 = \lceil \frac{n}{2} \rceil + \lfloor \frac{n}{2} \rfloor$
- 二维化的 CBT 恰是层序遍历的结果
代码模板
| |
哈夫曼树 Huffman Tree
首先应了解以下内容:
- 问题背景:合并果子问题,最短前缀编码问题
- 一些概念:
- 路径长度:从根节点出发到该节点所经过的边数
- 带权路径长度(Weighted Path Length):节点权值与路径长度的乘积
- 前缀编码:为给定的确定字符串中的字符编码时,任一个字符的编码都不是其他编码的前缀的编码形式;在哈夫曼树中,令左边为 0,右边为 1 可生成任一叶子节点的前缀编码
- 最优二叉树:也就是哈夫曼树,因其满足前缀最短,所以称最优
- 哈夫曼树的性质:
- 不存在度为 1 的节点
- 权值越高的节点越靠近根节点
- 任何一个叶子节点的编码都是唯一的,也即,满足前缀编码要求
实现方面,如果从零开始实现,代码量较大,可以根据具体问题选择部分实现哈夫曼编码的功能。以下实现方法从简单到困难递增。
- 方法一:使用 priority_queue
- 特点:并未实现树的结构,只是求出了根节点的权值
- 适用问题:“合并果子”
- 具体实现:用 STL 构建小数优先的优先队列,按照 BFS 的思想逐渐合并即可
- 方法二:使用 priority_queue + binary_tree_node
- 特点:既能实现哈夫曼树的所有功能,编码又相对简单
- 适用问题:前缀编码,合并果子
- 具体实现:见下
- 方法三:使用 heap + binary_tree_node
- 特点:可以从 0 完整的实现哈夫曼树,但编码困难
- 适用问题:前缀编码,合并果子
- 具体实现:以指向二叉树节点的指针为权值建立小顶堆,构建哈夫曼树即可
方法二的具体实现,包括四方面的需要掌握:
- 二叉树:
- 节点定义
struct Node - 新建节点
Node* new_node(int val)
- 节点定义
- priority_queue
- 比较函数
struct cmp:记住和 sort 的 cmp 反着来即可 - 定义队列
priority_queue<Node*, vector<Node*>, cmp> q;
- 比较函数
- 哈夫曼树
- 合并函数
Node* merge(Node* a, Node* b):合并两个节点 - 编码生成
void gen_code(Node* root, string init):生成哈夫曼编码
- 合并函数
- 主函数:依照 BFS 的思想,一直合并最小的两个节点即可
代码模板
| |
普通的树 Normal Tree
一般的树 General Tree
树这一类的题往往联系四种遍历和 DFS 与 BFS。只要掌握好这些遍历和搜索即可轻松应对。
代码模板
| |
并查集 Union-Find Set
并查集实质上是由数组实现的一种树。其数据结构 set[x] = y 表示节点 x 的父节点为 y,当且仅当 x == y 时,x 或 y 是根节点。应掌握:
int find(int x):包括迭代和递归两种实现void union(int a, int b):合并a和b所在的两个集合- 路径优化:将所有节点都指向根节点,将查找速度优化到 O(1)。包括迭代和递归两种实现
代码模板
| |
图 Graph
基础知识 Basic Knowledge
术语 Terminology
- 同构 Isomorphism:顶点,边以及顶点和边的组合完全一致,但表现可能不同的图
- 连通的 Connected:无向图中,两个顶点间有路径相连
- 连通图 Connected Graph:任意两个顶点都连通的图
- 连通分量 Connected Component:图中的最大连通图
- 强 Strongly:用来修饰连通,是指在有向图中,两个顶点间互有路径才算联通
- 连通块:连通分量和强连通分量的统称
分类 Classification
- 按形态上划分
- 有向图 Directed Graph
- 无向图 Undirected Graph
- 按实现上划分
- 邻接矩阵 Adjacency Matrix:顶点数小于等于 1000 适用
- 邻接表 Adjacency List:顶点数大于 1000 适用
ps. 不管是邻接矩阵还是邻接表,都应该显式地既保存 a 到 b 方向的,又保存 b 到 a 方向的。就是说,从实现角度看,所有的图都是有向图,要把无向图看作是双向连通的有向图。
图的遍历 Graph Traversal
对图的遍历,要考虑最一般的连通性。熟练掌握以下两个模板:
深度优先搜索遍历
| |
广度优先搜索遍历
| |
最短路径 Shortest Path
迪杰斯特拉算法 Dijkstra’s Algorithm
解决问题:边权非负的单源最短路径问题, i.e. Single Source Shortest Path(SSSP) Problem
伪代码:
| |
扩展问题:
在核心代码求最短距离的基础上,就是说不改变问题的首要目的——求 start 到任意节点的具有最小边权和的路径,可以在步骤二处增加数组以解决这些问题:
- 最短路径:增加数组 pre[]
- 增加边权:如边权代表花费多少,增加数组 cost[]
- 增加点权:如点权代表资源多少,增加数组 weight[]
- 最短路径数量:增加数组 cnt[]
简单地在步骤二处增加数组会增加编码难度,可以采用分而治之的思想。首先利用迪杰斯特拉算法求得一个vector
其他注意事项:
- 最短路径问题是贪心算法,存在局部最优即全局最优的情况
- 迪杰斯特拉算法的两个核心步骤都要求去找未被访问的节点
- 算法正确性证明:归纳法 + 反证法
- 算法复杂度在 $O(V^2 + E)$,如果内层找未访问的最小顶点利用优先队列实现,可降低复杂度到 $O(VlogV + E)$,这称为堆优化的迪杰斯特拉算法
贝尔曼-福特算法 Bellman-Ford Algorithm
解决问题:
有负权边的单源最短路径问题, i.e. Single Source Shortest Path Problem with Negative Weight Edge
代码模板:
| |
一些注解:
- 负环:顶点首尾相连形成环,环上边权和为负数
- 存在负环 -> 存在顶点没有最短路径;存在最短路径 -> 无负环
- 算法正确性证明:存在最短路径 -> 路径上的顶点数小于总顶点数 -> 最短路径树的高度小于总定点数
- 优化方法:若某轮操作都不进行松弛,则可以提前返回
- 算法复杂度为 O(VE)
关于统计最短路径条数:
由于有 n - 1 此操作,所以不能按照 Dijkstra’s Algorithm 的做法每次 + 1,而应定义 set
最短路径快速算法 Shortest Path Faster Algorithm (SPFA)
算法本质:并不能单独称之为一种算法,仅仅是 Bellman-Ford Algorithm 的一种队列优化形式。其优化思路是:因为只有当某个顶点 u 的 d[u] 值发生改变时,从 u 出发的边邻接的 v 的 d[v] 值才可能发生改变,因此可以建立队列保存应当判断是否需要松弛的节点
代码模板:
| |
代码模板中要注意的:
- 代码中含
ANCHOR的行可以删除,如果实现确定图中不存在负环 IN-QUEUE PROCEDURE要重点注意,如果还有具体问题要求的不仅仅是距离最短,还存在其他标尺,那么如果这个标尺是对其他节点有影响的,条件子句中还要进行IN-QUEUE PROCEDURE
一些注解:
- SPFA 时间复杂度平均 O(kE), k 大多不超过 2;但若存在负环,则会退化到 O(VE)
- Bellman-Ford 算法因为遍历了所有的边,所以可以判断源点可达、不可达的负环;但 SPFA 则只能判断源点可达的负环。为判断源点不可达负环:可以添加辅助顶点 C,添加源点到 C 的边、C 到其他 V-1 个顶点的边
最短路径 经典例题:
PAT A1003 “Emergency”,点此处,并在以下目录 solutions/solutions-PAT/A1003.cpp 中查看题解。
弗洛伊德算法 Floyd’s Algorithm
解决问题:不含负环的全源最短路问题,i.e. All Pairs Shortest Paths (APSP) without Negative Cycle
问题约束:MAXV 不超过 200,因此可以使用邻接矩阵
伪代码:
| |
算法正确性证明:暂不谈证明。思考中介点枚举为什么不能放在最内层循环?
最小生成树 Minimum Spanning Tree
基础 Basis
定义 Definition:
在无向图 G(V, E) 中找到树 T,使得:
- T 包含 G 中所有顶点、
- T 中所有的边都来自于 G 的边、
- T 边权之和最小。
称树 T 为 G 的最小生成树。
性质 Property:
- 最小生成树是树,边数等于顶点数减一
- 最小生成树不唯一,但最小边权和唯一
- 图中任何节点都可以作为最小生成树的根节点
普里姆算法 Prim’s Algorithm
原理 Theory:
与迪杰斯特拉算法原理相同,将 distance[] 数组的含义改为距已经成为最小生成树的部分的最短距离,同时将松弛操作部分作对应修改即可。
时间复杂度 Time Complexity:
$O(V^2)$,若采用邻接表及堆优化,则优化到 $O(VlogV +E)$
伪代码 Pseudo Code:
| |
克鲁斯卡尔算法 Kruskal’s Algorithm
原理 Theory:
采用边贪心策略,每次都获取最小边,将其连通到当前最小生成树上。具体实现上使用并查集。
时间复杂度 Time Complexity:
$O(ElogE)$
模板 Template:
| |
拓扑排序 Topological Sort
基础 Basis:
- 有向无环图 Directed Acyclic Graph(DAG):字面意思
- 拓扑排序 Topological Sort:对于 DAG G(E, V),对任意 u,v ∈ E,若存在边 u → v,则将 u 排在 v 的前面。按这种逻辑进行的排序称拓扑排序
原理 Principal:
将拓扑排序类比为大学课程的修读顺序安排。则如果某门课程无先导课程或其先导课程已全部修完,则这门课程就可以修读。
模板 Template:
| |
注意 Tips:
- 代码 ANCHOR 行有时非常重要,尤其是在连续输入多组数据时,需要复原变量,这个时候 ANCHOR 行可以直接复原。但是如果存在 num < n 时的情况,则 ANCHOR 行不能完全清空 adj 变量,最好的方法是单独定义清空函数
- 根据原理,可以实现出不同版本的拓扑排序,包括 bfs,dfs,栈,贪心法(暴力法)等形式。各有优劣及适用情景
关键路径 Critical Path
基础 Basis:
- 顶点活动(Activity On Vertex,AOV)网:用顶点表示活动,用边表示活动间优先度的图。
- 边活动(Activity On Edge,AOE)网:用带权边表示活动及其用时,用顶点表示事件的图。任何 AOV 网都可转换为 AOE 网。
- 活动 Activity:指任务、课程、工程等
- 事件 Event(常用 V 表示):指任务、课程、工程等的完成与否、完成量等的状态。在 AOE 网中,一个节点即状态,表示其所有前序活动均完成。
- 关键路径 Critical Path:在 AOE 网中寻找到的一条或多条最长路径
- 关键路径树:所有关键路径组成的一颗树,如果只有一条关键路径,则退化为一维序列
- 最长路径问题 Longest Path Problem:求关键路径的问题
- 活动最早开始时间 $e_i$
- 活动最晚开始时间 $l_i$
- 事件最早开始时间 $ve_i$
- 事件最晚开始时间 $vl_i$
- 关键活动 Critical Activity:关键路径上的活动,即不允许拖延的活动。对任意关键活动总有 $e_i = l_i$
- 源点 Source Vertex:AOE 网中的起点,i.e., a vertex with indegree zero
- 汇点 Sink Vertex:AOE 网中的终点,i.e., a vertex with outdegree zero
求法 Solution:
解决问题:求解 DAG 的最长路径
原理 Principal:
$V_u\stackrel{a_r}{\longrightarrow}V_v$
- 因为
e == l,所以要求e和l - 因为
e = ve[i]及l = vl[j] - a.time,所以要求ve[]及vl[] - 因为
ve[v] = max(ve[u] + time[r])及vl[u] = min(vl[v] - time[r]),所以要求正反拓扑序列来求
步骤 Step:
- 使用
topological_sort()获得正拓扑序列topo_order[],计算ve[] - 如果未知汇点,找到汇点,获得关键路径长度,
critical_legth - 使用反拓扑序列,计算
vl[] - 根据
e,l,ve,vl间的关系,获得关键路径树cpt[] - 返回关键路径长度,如果不存在返回
-1
模板 Template:
| |
例题
Codeup 100000624-00 题“关键路径”,点此处,并在以下目录
solutions/solutions-CODEUP/100000624-00.cpp中查看题解。
动态规划 Dynamic Programming
术语 Terminology
- 最优化问题 Optimization Problem:根据约束条件求得最优结果。
- 多阶段决策问题 Multistage Decision-making Problem:最优化问题的一种,可以将问题划分成相关联的若干阶段。
- 阶段 Stage:按照有限自动机的思想理解,阶段=结点+有向线段。
- 状态 State:按照有限自动机的思想理解,状态即结点;也可以将状态理解成子问题的解。
- 决策 Decision-making:按照有限自动机的思想理解,决策即有向线段。
- 记忆化搜索 Memory Search:边搜索边保存状态。
- 状态转移方程 State Transition Equation:描述状态和状态间转换的方程。设计该方程是动规的核心。
- 重叠子问题 Overlapping Subproblem:问题可以分为若干子问题,且子问题重复出现
- 最优子结构 Optimal Substructure:问题的最优解可以通过子问题的最优解有效构造出来。
- 贪心选择性 Greedy Choice Property:一个问题的整体最优解可通过一系列局部的最优解的选择达到,并且每次的选择可以依赖以前作出的选择,但不依赖于后面要作出的选择。
- 无后效性 Non-aftereffect Property:状态只影响下一个状态,而不影响之后的。状态转移方程应当满足该性质。
方法 Approach
- 自顶向下的方法 / 递归 Top-down Approach / Recursion
- 自底向上的方法 / 递推 Bottom-up Approach / Iteration
比较 Comparison
| 方法 | 理解 | 比较 |
|---|---|---|
| 分治 Divide-and-Conquer: | =非重叠子问题 | 可以解决非优化类问题,比如归并排序 |
| 贪心 Greedy Algorithm: | =贪心选择性+最优子结构 | 每一步不必依靠上一步的解 |
| 动态规划 Dynamic Programming: | =重叠子问题+最优子结构 |
注意 Note
DP 算法最好选择从 1 开始计数,因为下标为 0 时往往是边界
字符串 String
有限状态机 Finite State Machine
针对字符串处理的相关题目,可以使用 FSM 解决。首先分清楚两个概念
- 有限的状态节点
- 表示状态转移条件的有向边
在做题时,首先定义好要解决问题的字符串模式,接下来定义有穷的状态码及其内涵,最后找到所有的可状态转移条件。
例子
PAT B1003 “我要通过”,点此处,并在以下目录
solutions/solutions-PAT/B1003.cpp中查看题解。其 FSM 图如下:PAT A1060 “Are They Equal”,点此处,并在以下目录
solutions/solutions-PAT/A1060.cpp中查看题解。
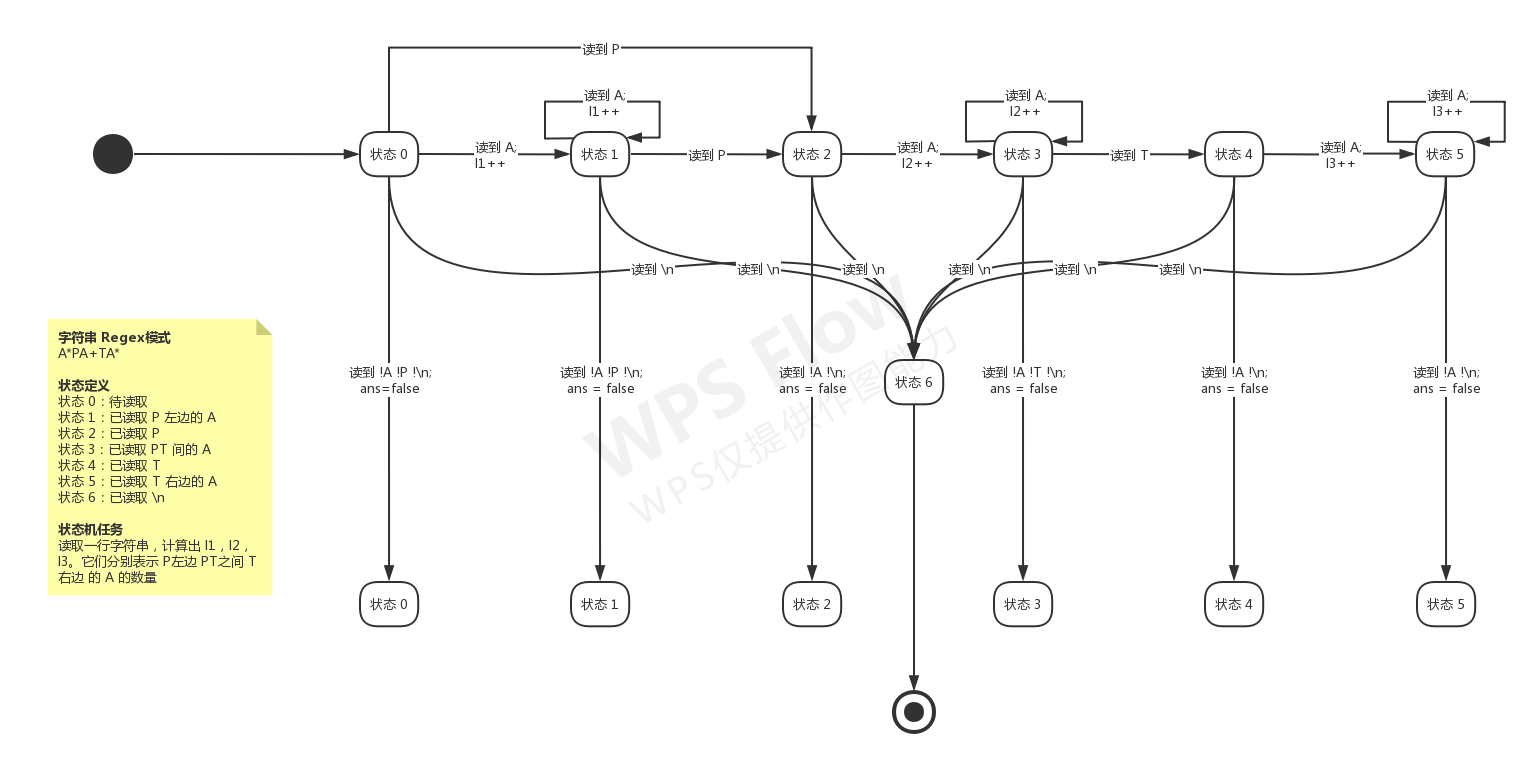
KMP 算法 Knuth–Morris–Pratt string-searching algorithm
代码模板
| |
Citation
@article{shichaosong2021cc,
title = {C/C++ 语言算法与数据结构学习笔记},
author = {Shichao Song},
journal = {The Kiseki Log},
year = {2021},
month = {February},
url = {https://ki-seki.github.io/posts/210205-algorithm/}
}
References
胡凡, and 曾磊. 算法笔记. 机械工业出版社, July 2026. ↩︎