)](https://ki-seki.github.io/posts/260531-lilian-rl-overview/RL_illustration_new.png)
Fully Annotated Guide to "A (Long) Peek into Reinforcement Learning"
This is a fully annotated guide to Lilian Weng’s post A (Long) Peek into Reinforcement Learning.
This is a fully annotated guide to Lilian Weng’s post A (Long) Peek into Reinforcement Learning.
)](https://ki-seki.github.io/posts/260430-multi-armed-bandit/multi-armed-bandit.png)
The multi-armed bandit problem is a classic exploration–exploitation dilemma in reinforcement learning. Lilian Weng’s post is an excellent introduction, but some mathematical details and motivations can be cryptic. This article annotates it with step-by-step explanations and supplementary notes.
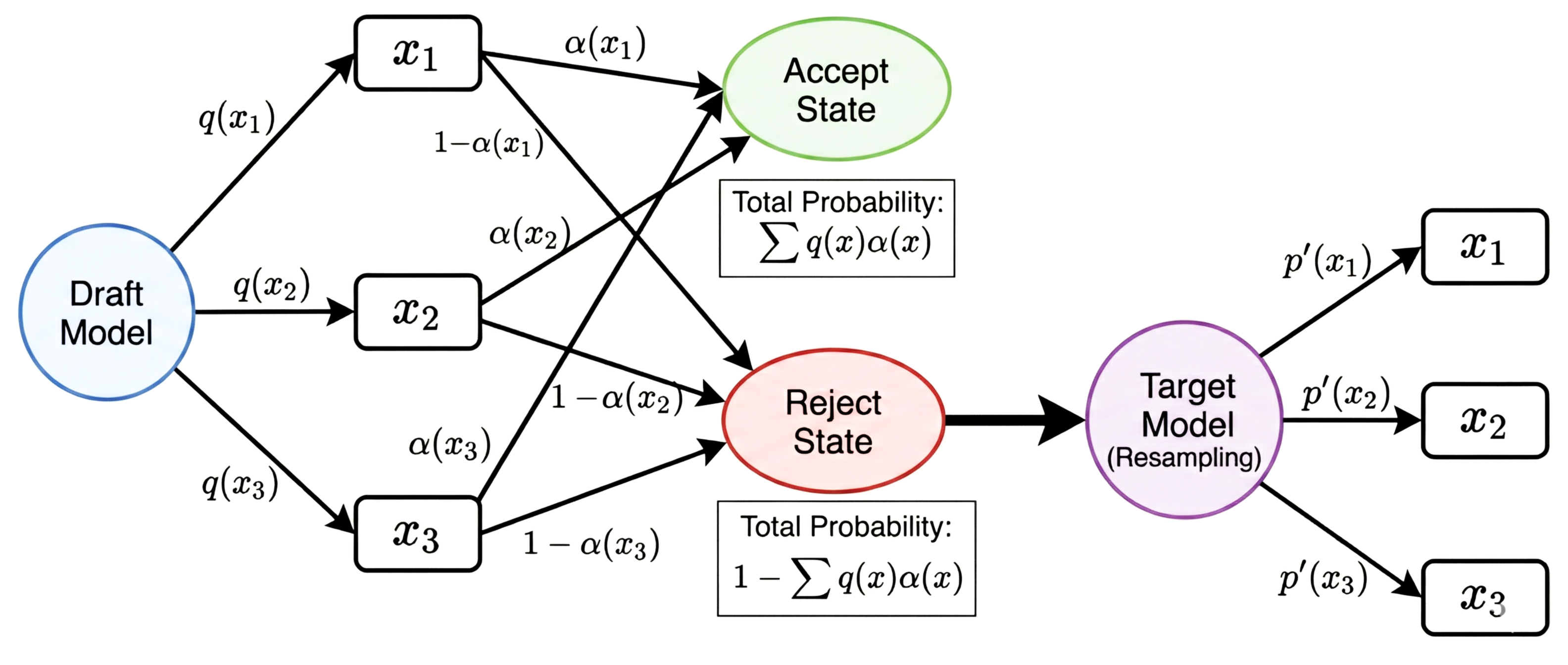
A simple mathematical derivation of the algorithm construction process from the paper “Fast Inference from Transformers via Speculative Decoding”.
](https://ki-seki.github.io/posts/250902-diffusion-annotated/Diffusion_Diagram.png)
Diffusion models are the de facto standard for image generation. Lilian Weng’s “What Are Diffusion Models?” is an excellent introduction to it, but readers without a solid mathematical background may struggle. This article fills that gap with clear, step‑by‑step derivations and explanations.